您现在的位置是:首页 > 特别推荐 >
性能提升300%|分秒帧基于云器Lakehouse升级一体化数据平台
2023-11-29 16:28:37作者:来源:企业网D1Net
摘要 分秒帧是为音视频创作者打造的一款云端生产协作平台,提供一站式音视频协同创作服务,是新一代云时代音视频生产协作SaaS。可帮助创作 ...
分秒帧基于云器Lakehouse,以Single-Engine一体化数据平台代替了原有三条链路拼装而成的数据平台,全面提升数据响应速度,实现产品服务再升级。通过云器Lakehouse,基于湖仓一体实现了存算分离,消除数据冗余,存储与计算成本降低60%以上;通过增量计算实现全域数据实时化,端到端实现秒级数据新鲜度,简化数据处理链路,降低使用成本50%以上。
分秒帧数据平台发展和架构痛点分析
分秒帧技术部门需要支撑内部业务系统、市场、运营、销售、客户成功等多个部门的BI报表分析,早期采用Spark做离线表报,随后逐步增加了Spark streaming、Kafka、Clickhouse等开源大数据组件,以满足OLAP分析以及实时BI看板场景,最终形成基于Lambda架构搭建的数据平台。升级前架构如下:
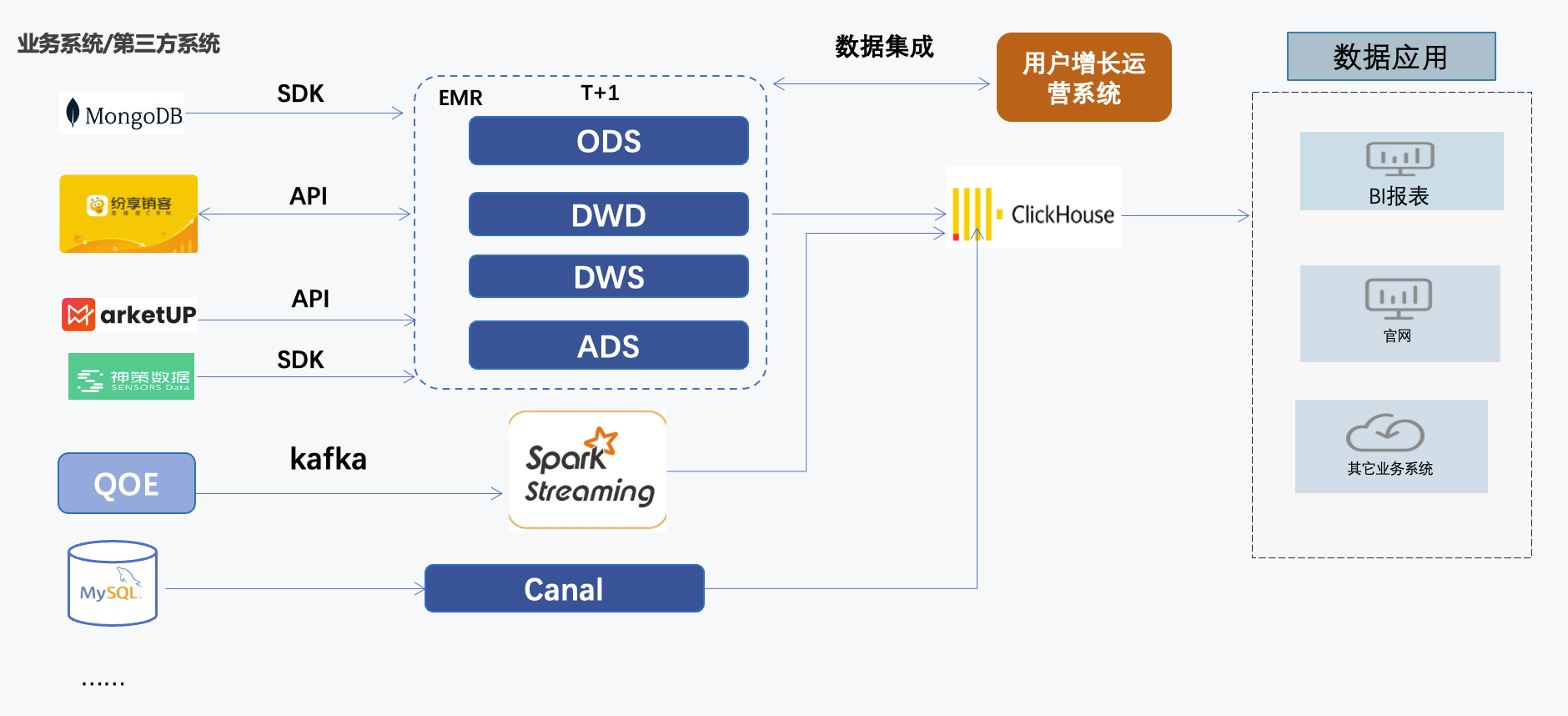
基于业务需要,我们的数据平台持续接入多端跨平台的数据,持续对接了比较多的组件且还在不断增加中。平台的数据架构逐渐变得复杂,运营和维护成本较高,查询性能出现瓶颈。总结具体的问题总结为以下三个方面:
1、数据类型复杂,多种形态数据整合难。官网流量数据、CRM的客户跟进关系数据、神策采集的产品行为日志、广告平台投放效果等多方系统平台数据分散在数据湖与数据仓库中,包含大量文本、音频、视频等半结构化与非结构化数据,存在业务口径、数据指标二义性、打通成本极高等问题。企业全域数据无法形成完整的用户画像,导致业务前后链路难以形成有效闭环。
2、离线与实时分析共存带来数据冗余、治理困难。原数据平台要支持传统的离线分析,要支持实时分析,还要做各类复杂场景分析,包括用户行为分析、会员留存与裂变分析等。为了支持QOE视频播放质量的实时分析,会将QOE数据在EMR平台、Clickhouse等多条链路重复存储,造成50%以上的冗余,数据治理困难。
3、数据接入和etl处理架构复杂,开发运维成本较高。多条数据链路造成数据有多份,后期开发和运维成本高。我们原有的数据平台使用了Clickhouse与EMR等开源产品,整体属于业界常见的Lambda架构,架构上有传统批处理的ETL作业,也有为了实时场景的spark streaming和其专用的数据链路,同时还有其他几条数据链路。我们认识到lambda架构方案一直在做架构的“缝合”,造成大量存储冗余是主要的痛点。
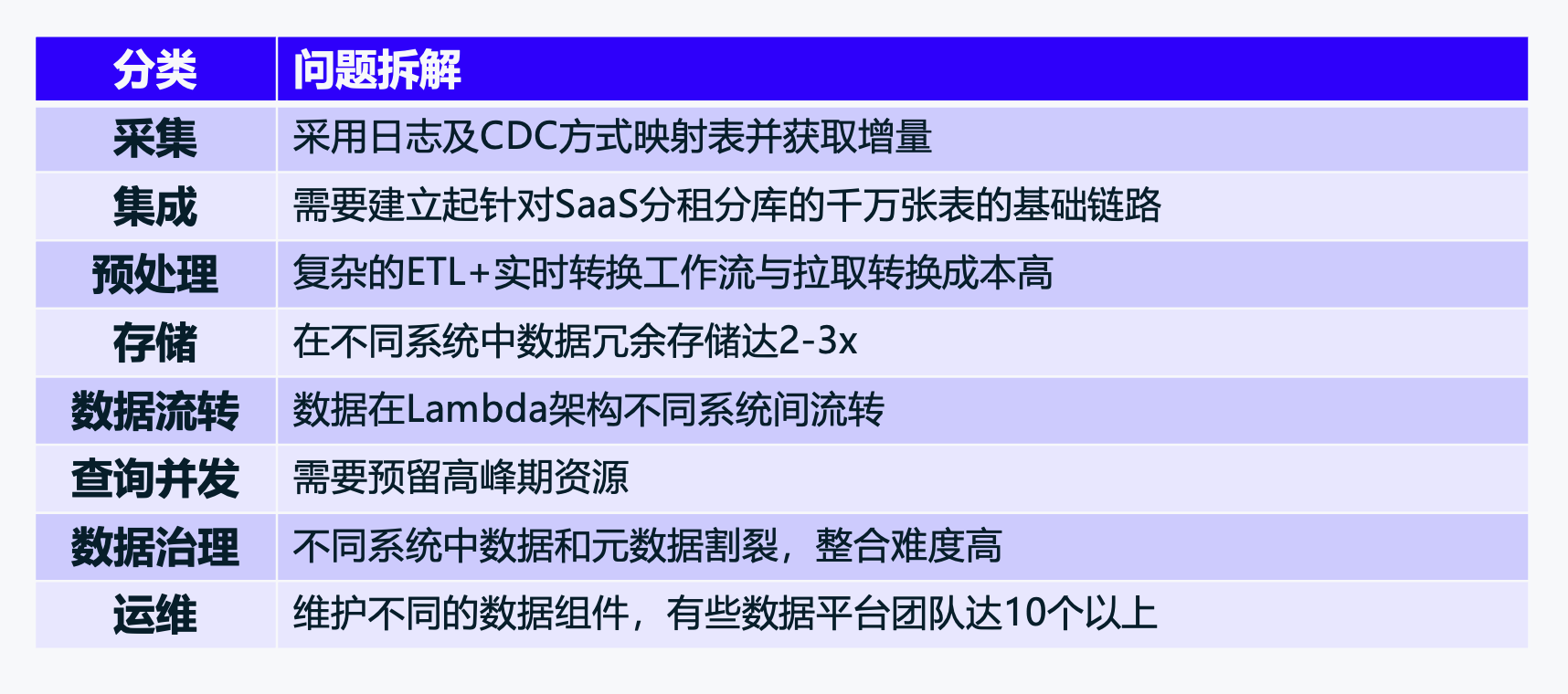
盘点成本问题,我们重新梳理了整个数据链路,从采集到最后运维的整条链路,总结了原架构造成高成本的原因(见下表),可见企业的数据链路成本问题不仅仅是计算成本,运维成本,架构和数据各个链条上,都有成本问题需要考虑。我们认识到,用全开源方案在单个点上或许可以达到成本的优化,而从整体链路来看,成本问题要系统性统一的解决才更合理。
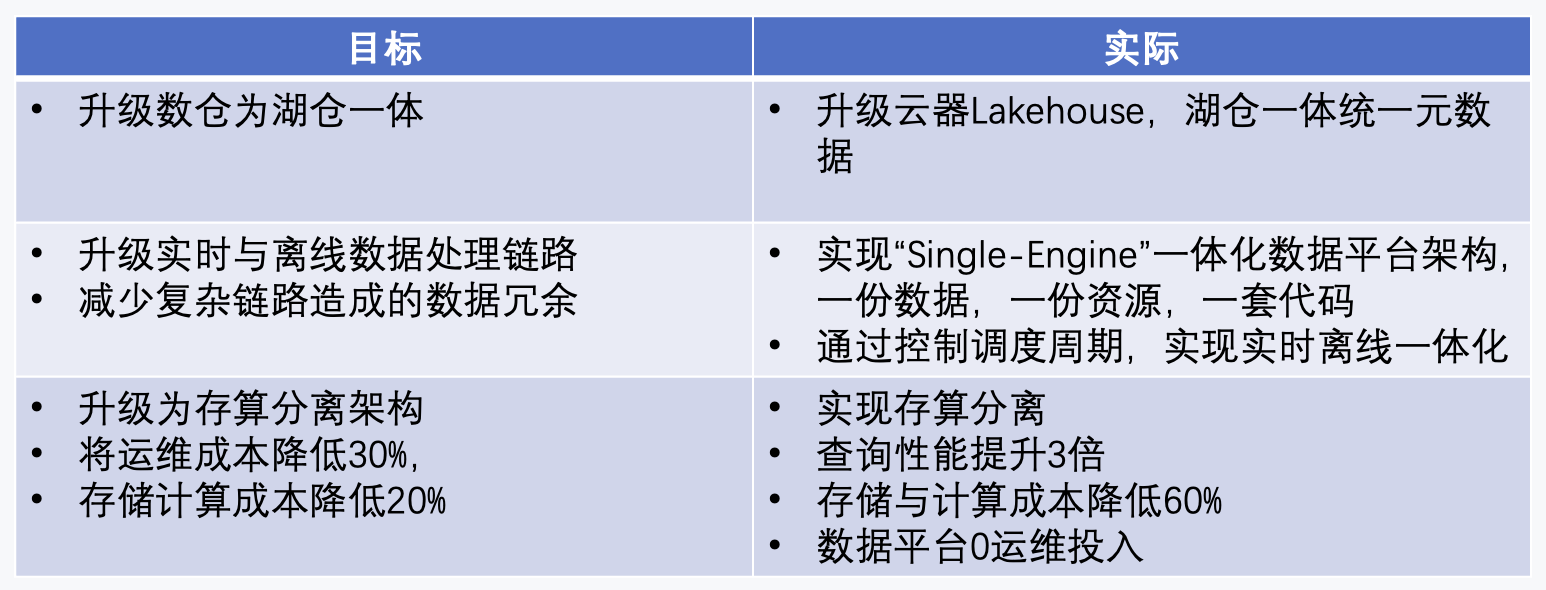
为了解决以上问题,我们决定对数据平台进行升级,期望能满足以下几个目标:
• 架构升级:合并实时与离线数据处理链路,形成全链路实时化,减少复杂链路造成的数据冗余;
• 存储升级数仓为湖仓一体,满足面向未来的半非结构化数据存储以及AI能力建设;
• 整体降低成本:目标将运维成本降低30%,存储计算成本降低20%;
• 从自建到托管:公司战略上倾向不再自建数据平台,而是寻找托管型产品,尽量降低维护人力成本。
why云器
在2022年,我们启动了数据平台的升级选型工作,并最终选择了云器。在选型过程中我们了解到云器Lakehouse数据平台,“Single-Engine”一体化的技术理念和我们想要简化架构的目的相契合,减少开发运维成本;有开放式湖仓一体存储,可以方便我们统一元数据管理,兼容我们非结构底层数据,同时兼顾未来AI和ML的应用场景;同时它是全托管免运维的数据平台,可免去我们繁琐的系统运维升级工作。
最打动我们的点是了解到资源和运维成本可大幅降低。
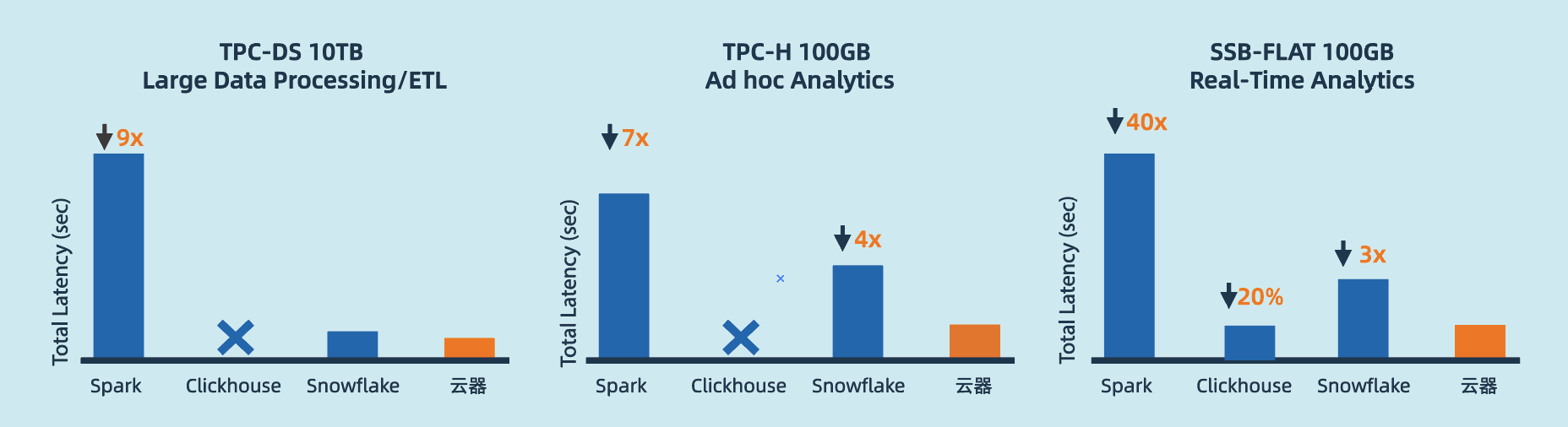
我们也比较了云器Lakehouse的性能,根据公开数据可以看到,其在离线批处理场景中,性能比Clickhouse快20%,流计算比Flink节省10-1000计算成本,且无需系统转换即可实现离线、实时数据链路的无缝切换。
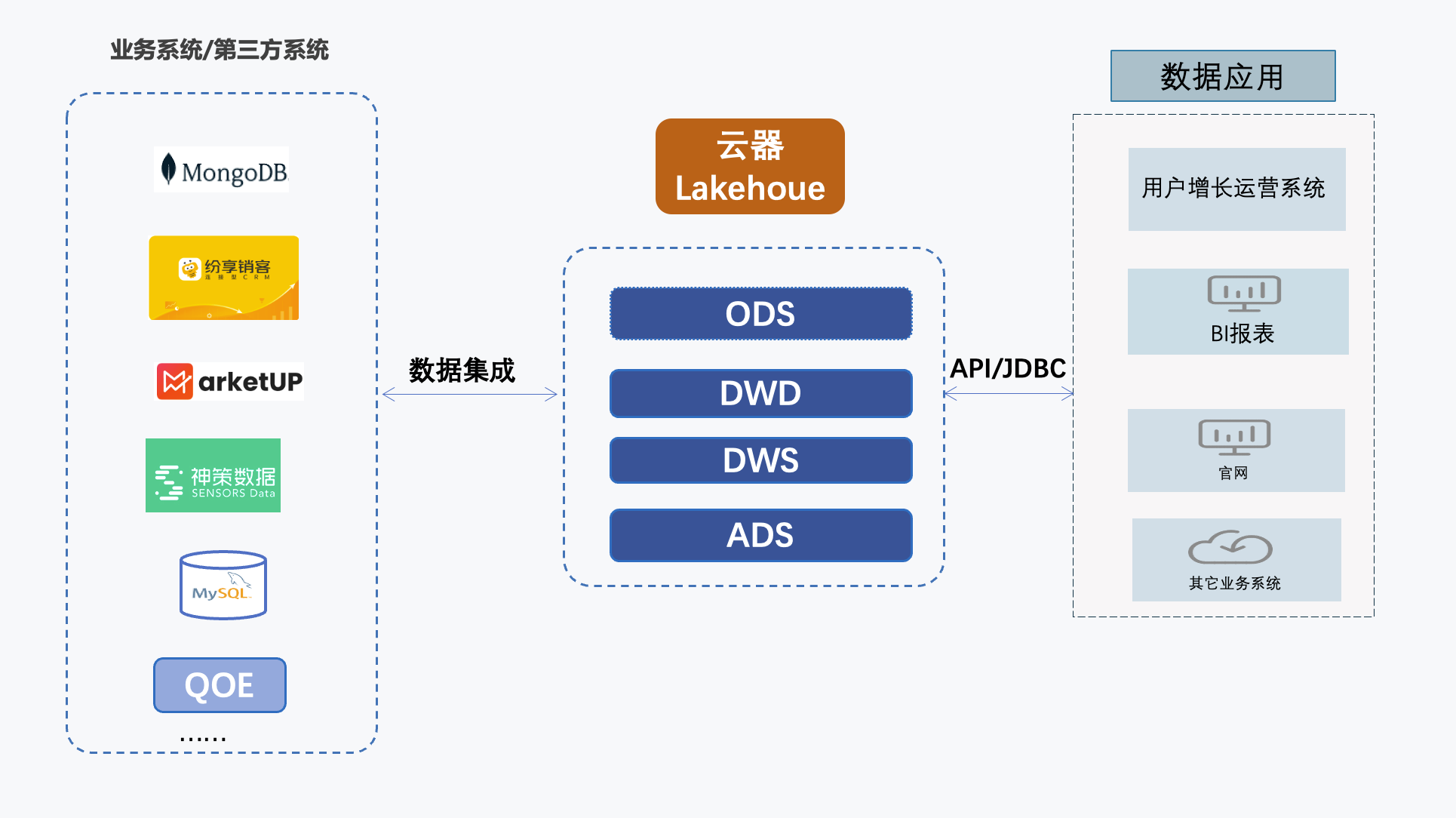
升级后的架构
对比原有方案,Clickhouse和EMR存在各自的制约和问题也得到了解决
• Clickhouse对单表大型数据查询表现优秀,但对多张业务表做联合查询存在限制,一旦涉及多表联查,支持不太友好,查询效率就急剧下降。
• EMR处理一条复杂的ETL处理需要耗时半小时以上,hive SQL查询语句存在性能瓶颈,hive 无法满足部分时效性要求较高的场景。
云器Lakehouse在交互式分析可以支持多表查询替代clickhouse,同时有不错的性能;在批处理分析的负载任务也可以替代EMR。且新的数据架构并不需要建立多条数据链路,解决了数据冗余的问题,相当于帮助我们做了数据治理优化,让整个架构变得清爽很多。
基于云器Lakehouse升级后的新平台的升级效果:
数据平台升级后,我们实现了:
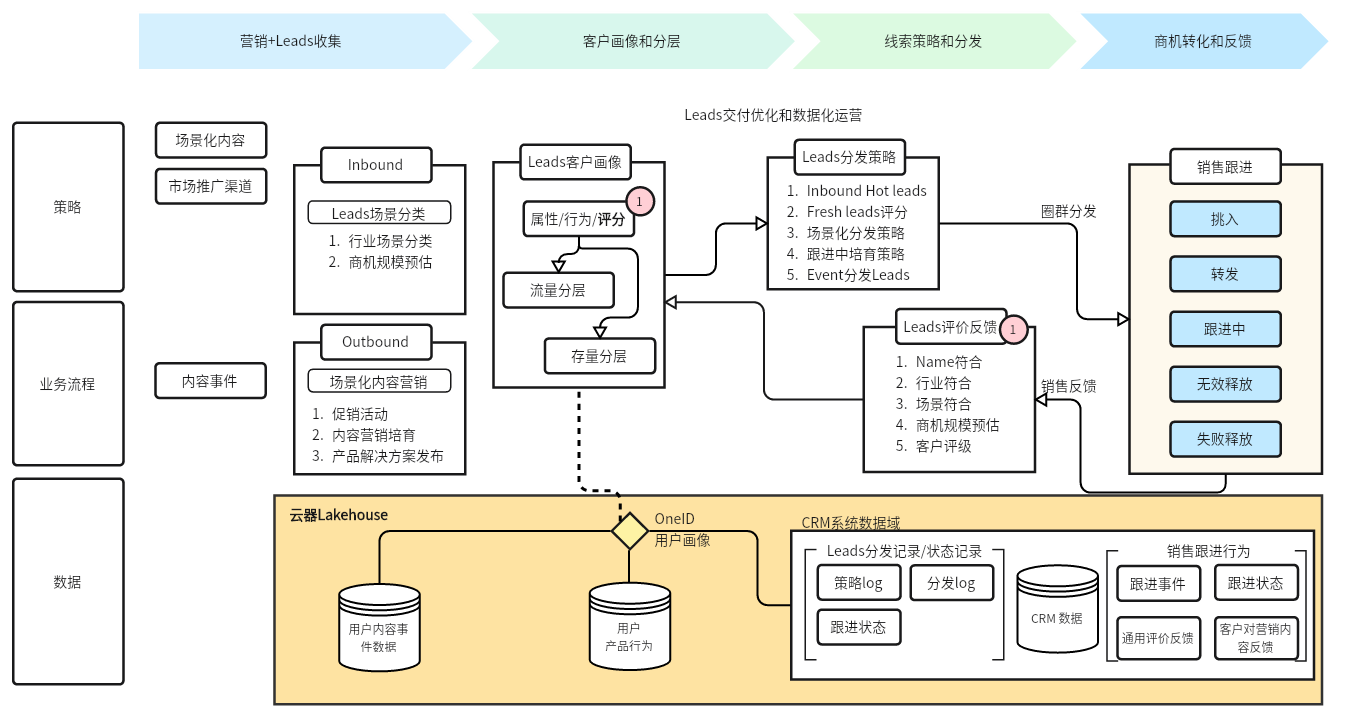
1、数据资产统一,支持业务转化,挖掘数据的运营价值。湖仓一体以及一体化平台,能更容易的把全域数据整合在一起,发挥更多数据的业务价值。例如我们通过云器的OneID能力,整合多种类型的文本、日志等半/非结构化数据,形成统一的用户模型,以便更好地分析和挖掘数据价值。以下图为例,通过Single-Engine的能力将神策的用户行为日志数据(半结构化数据)统一集成,经过ETL加工处理,与官网、产品以及CRM数据整合打通,形成360°用户画像,建立评分模型挖掘潜在用户和新流量机会,提供不同人群的运营策略。
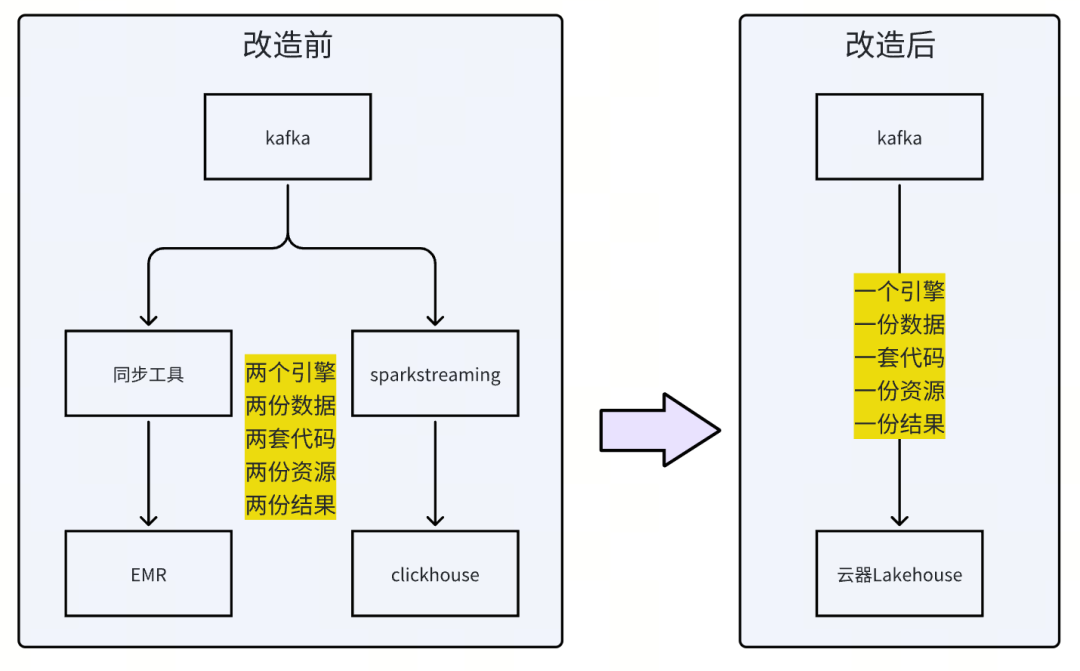
2、实现了低成本的实时离线一体化。针对离线与实时两条链路的问题,我们基于云器Lakehouse的“增量计算”技术,实现更极致的一体化,一个引擎、一份数据、一套代码,基于实际需求,灵活调整整条链路的数据刷新频率,替换掉高成本独立资源的EMR与Sparkstreaming,带来了大幅的成本下降。
3、数据平台架构得到简化,降低了平台复杂度。升级后的一体化湖仓平台,代替原有Kafka+Sparkstreaming+Clickhouse、与Mysql+binlog+canal+Clickhouse的技术方案,一套引擎满足多个复杂场景,缩短链路,减少了运维成本。如下图示:
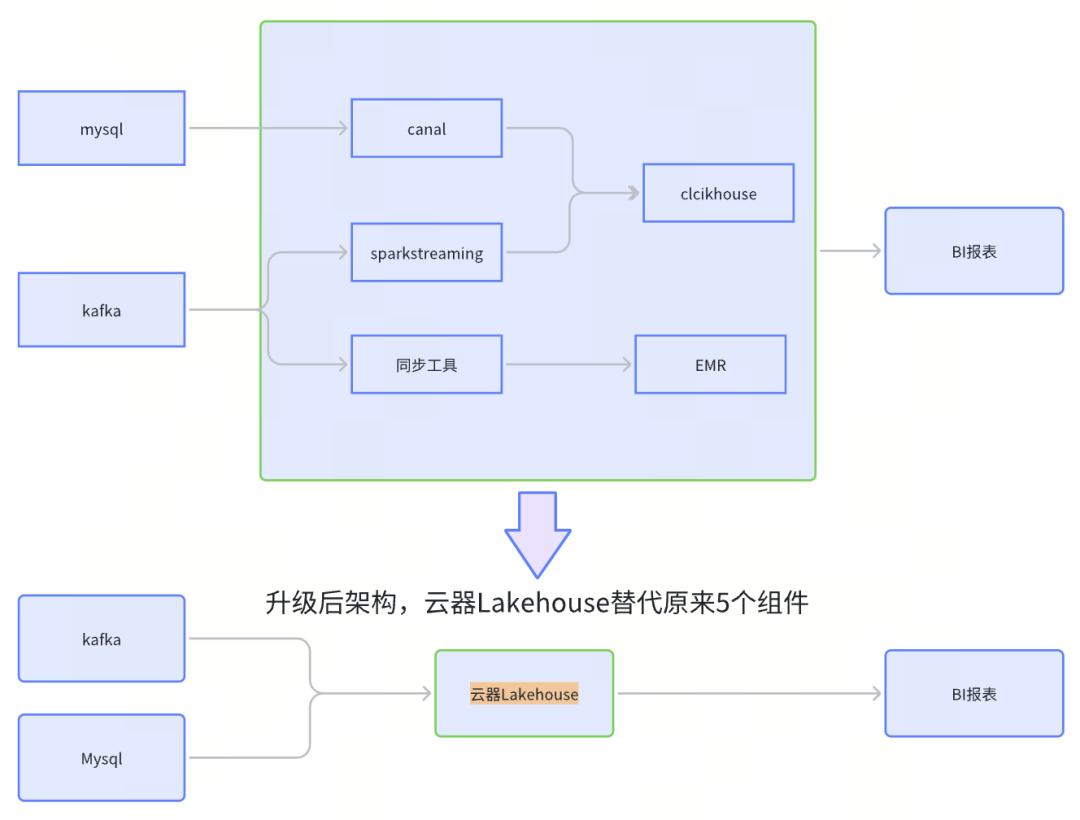
原有平台架构升级后,一个云器Lakehouse替代了原先5个组件,极大降低了平台复杂度。
4、存储与计算成本降低60%以上,查询性能提升3倍。云器Lakehouse的存算分离架构通过更高效的数据存储方式和压缩算法,平台的存储成本降低了60%以上;在计算成本方面,支持弹性扩缩容,按需计费模式,平台的计算成本降低了60%以上;在开发和运维成本方面,云器Lakehouse是全托管的SaaS化数据平台,统一采用才SQL语言进行开发,免运维投入,让平台的开发和运维成本显著降低。
数据平台升级后的业务价值:
1、全域数据资产整合。基于云器Lakehouse一体化数据平台,将不同源、不同类型的数据统一到一个集中存储库中,以实现统一用户画像,完成了自动化线索管理闭环,从市场、到产品、再到客户成功整个链路形成完整闭环,数据洞察更精准,挖掘潜在用户与机会,提供不同人群运营策略,为客户提供更好的数据服务,更方便、理解自己的数据资产。
2、提升数据新鲜度梯度。分级设置数据的刷新调度,以供不同场景的业务决策使用。业务看板可以根据需要从T+1提升到H+1/M+5,上层业务应用可以进行实时标签计算、指标统计,使业务各个部门人员实时/准实时进行探索、报表统计。
3、业务更灵活的支持应用场景。新平台中,用户可以用一套SQL进行数据开发,以及系统基于MV on MV自动刷新数据处理链路,让整个数据开发工作变得更简单,业务协作更高效。
总结和展望:
分秒帧通过使用云器Lakehouse,大幅简化了技术架构,由Lambda架构转变为Kappa架构,达成了降本增效的目标,从集成、开发到运维成本整体下降,且在将运维托管给云器后,释放了数据团队的运维工作量,让懂数据的团队可以更专注在数据业务创新和决策支撑上。
同时我们也感受到使用云器Lakehouse作为全托管产品的便利,例如在一些功能点上,能肉眼可见的看到产品在不断迭代升级,我们提出了一些功能升级的需求,也得到了云器产品团队的反馈,以下是我们期待云器升级的功能点,据了解已经排在了产品升级日程上:
• 增量计算场景宽度提升:提供MV实时任务的运维能力,同时支持实时任务补数以及schema变更场景
• 自定义函数支持:拓宽支持JAVA/Python语言的UDAF和UDTF自定义
总的说,这是我们使用云器Lakehouse的经验,供数据架构团队选型参考。
(本文不涉密)
责任编辑:
特别推荐





 |
站点信息
- 运营主体:中国信息化周报
- 商务合作:赵瑞华 010-88559646
- 微信公众号:扫描二维码,关注我们
