您现在的位置是:首页 > 行业 > 制造 >
面向离散制造业数据挖掘技术研究与应用
2009-10-29 22:29:00作者:王建良 杜元胜 徐建良来源:
摘要在对离散制造企业生产过程中的物流数据特点进行充分分析的基础上,利用数据挖掘技术建立面向零部件物流成本的供应商选择优化模型;研究了针对应用问题的关联规则处理策略以完成对所发现知识的理解和利用;提出了改进的Apriori算法并研制一个数据挖掘系统平台来对此构想进行具...
1 引 言
典型的离散制造企业是面向单一定单的主要从事单件、小批量生产的企业。其特点是多品种和小批量,如大型汽轮机业、压缩机、石油机械等。产品的工艺过程经常变更使得购买原材料的资金占用很大。企业在进销存管理方面应该有良好的管理机制和工具,用于接收的订单、检查库存状况、采购材料、调整库存物数量,从而为产品生产做好前期工作,并在产品生产完成后及时出货等。在经济全球化进程中,企业间的竞争己经转变为供应链之间的竞争。
山东半岛作为中国最大的制造业基地,每天有成千上万企业的产品源源不断地流向世界各地。企业为了追求最大的利润无不纷纷采用ERP系统以提高管理手段。在此基础上企业越来越重视研究找到能最大限度满足某定单需求的原材料供应商以提高生产效率、降低生产成本。
一个供应商能够提供多种零部件,一种零部件也有若干不同的供应商。对于一个供应商,可能在不同零件的候选供应商列表里的级别分类不同。也就是说相对于采购企业而言,某些零部件产品是值得被优先考虑采购的,另外一些零部件产品是处于次选的。在正确的时间、正确的地点向正确的客户提供正确数量和类型的物品,就是目前开始兴起的精益供应链管理(Lean Supply Chain Management)。
本文的工作就是用数据挖掘技术的关联规则来对以上所述的问题加以实现。随着数据库技术的迅速发展以及广泛应用,现代计算机技术与数据库技术已经可以支持存储并快速检索这样规模的数据库,高效地实现数据的录入、查询、统计等功能。但无论在时间意义上还是在空间意义上,传统的数据分析手段都无法发现数据中存在的关系和规则,根据现有的数据预测未来的发展趋势。缺乏挖掘数据背后隐藏的知识的手段,导致了越来越严重的“数据爆炸但知识贫乏”的现象。在这样的背景下,数据挖掘技术应运而生。
2 数据挖掘及其方法研究
2.1 数据挖掘
第11届国际人工智能联合会议首次提出了KDD(Knowledge Discovery in Databases,数据库中的知识发现)概念,而数据挖掘是它的核心。后来的国际人工智能联合会议都举行KDD专题讨论会,来自各领域的研究人员和应用开发者集中讨论数据统计、海量数据分析算法、知识表示、知识运用等问题。数据挖掘(Data Mining)是一种决策支持过程。它主要基于人工智能、机器学习、统计学等技术,高度自动化地分析企业原有的数据,做出归纳性的推理,从中挖掘出潜在的模式,预测客户的行为,帮助企业的决策者调整市场策略,减少风险,做出正确的决策。这种需求驱动力,比数据库查询更为强大。从功能上可将数据挖掘分析方法划分为:关联分析(Associations)、序列模式分析(Sequential Patterns)、分类分析(Classifiers)、聚类分析(Clustering)。
2.2 关联规则
数据关联是数据库中存在的一类重要的可被发现的知识。若两个或多个变量的取值之间存在某种规律性,就称为关联。关联可分为简单关联、时序关联、因果关联。关联分析的目的是找出数据库中隐藏的关联网。有时并不知道数据库中数据的关联函数,即使知道也是不确定的,因此关联分析生成的规则带有可信度。关联规则挖掘的描述如下:
设I={i1,i2,…,in}是所有数据项的集合,设D={T1,T2,…,Tn}为所有事务的集合,即一个事务数据库,其中的每个事务T是一个数据项子集,即T∈I。每个事务可以用惟一的标识符TID来标识。
设X为一个数据项集合,称为项集,包含k个数据项的项集称为k项集。当且仅当X∈T,称为事务T包含X。事务数据库D中数据项集X的支持度为:support(X)=P(X)=︱Tx︱/︱D︱,其中Tx=(T∈D=X∈T)。在用户给定的支持度阐值minisupport下,若support(X)≥minisupport,则称X为频繁项集,否则X为非频繁项集。一个关联规则是“X=>Y”形式的蕴含式,其中X=>I,Y=>I且X∩Y=φ。如果D中包含事务X∪Y的百分比为s,则称s为关联规则X=>Y的支持度,它是概率P(X∪Y)。如果D中包含X的事务同时已包含Y的百分比为c,则称c为关联规则X=>Y的信任度,它是条件概率P(Y︱X)。即:support(X=>Y)=P(X∪Y)=support(X∪Y);confidence(X y)=P(Y︱X)=support(X∪Y)/support(X)。挖掘关联规则的问题就是要生成所有满足support(X=>Y)≥minisupport和confidence(X=>Y)≥miniconfidence的关联规则,其中minisupport和miniconfidence分别为用户给定的最小支持度闭值和最小信任度闭值。同时满足这两个条件的关联规则称为强关联规则。
挖掘关联规则主要包含两个子问题:①从事务数据库D中生成所有的频繁项集;②根据获得的频繁项集生成强关联规则。事实上,挖掘关联规则的整个执行过程中第一个子问题是核心。当找到所有的频繁项集后,相应的关联规则将很容易生成,Apriori算法主要是处理第一个子问题。
2.3 Apriori算法及其改进
已有的关联规则发现算法中,最著名的是Agrawal等人于1993年提出的Apriori算法。Apriori算法是一种宽度优先算法。基本Apriori算法存在的问题是会重复、大量扫描数据库,生成多个耗费空间的候选项集,耗费大量运算时间。参考王暖浑等人的思想本文又提出改进算法:在扫描数据库产生候选项的同时直接生成所对应的频繁项集,如频繁项集不符合Apriori性质,立即删除。不经过先产生候选项集再生成频繁项集,有的一次性产生频繁项集,目的在于减少扫描次数,节省存储空间,减少运算时间。采用此改进算法可以使扫描次数大约减少1/2,大大节省了存储空问和运算时间。算法描述:根据Apriori性质,逐层迭代由候选项直接生成频繁项集。输入:供应商行为数据库D,最小支持度阑值minisup;输出:D中的频繁项集L,即满足要求的客户关联规则。
NewApriori:
begin
L1=find_ frequent_1-itemsets(D);
fork=2;Ik-1≠φ;k++)
Lk=apriori_gen(Lk-1;minsup);
return(L=UkLk)
procedurea piroir_gen(Lk-11requent(k-1)-itemsets;minsup;minimum_support_limited)
for eachitemsetset L1∈Lk-1
for eachitemsetset L2∈Lk-1
if(L1[1]=L2[1])^(LI[2]^L2[2]…L1[k-1]^L2[k-1])then
{C=L1joinL2
if has_frequent_subset(C,Lk-1)then
delete C;
else{
for each transaetiont D
Ct=subset(Ck,t);
for each candidate C E Ct
C.count++;
Lk=(C∈Ck-C.count≥minsup)
)}
return Lk;
procedure has_infrequent_subset(C:candidate k_
itemset;Lk-1:frequent(k-1)-item set)
for each(k-1)-subset S of C
if S∈Lk-1 then return TRUE;
return FALSE.
3 实 例
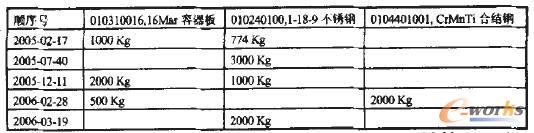
实际应用中,有如下数据模型。表1表示企业供应商全集,验证时有5万条记录;表2为合同98A04所需要的材料名称,材料编号与表一对应。为方便解释,选定一组数据描述见表3。
表1 供应商业务集(局部)
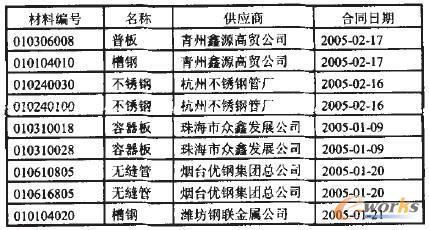
表2 订单及材料需求(局部)
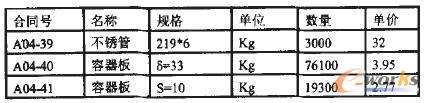
表3 潍坊A公司供货业务集(局部)
基于文中提出的模型和关联规则处理方法,我们设计和开发了“面向离散制造业的数据挖掘系统”。系统包含以下功能模块:建模用户定义、数据抽取、知识发现、模型求解、生成具体方案以及方案评价。该系统使用Java语言并在山东生建集团得到实际应用。
4 结 论
本文的创新点是提出了一种改进的关联规则数据挖掘算法。利用该算法挖掘非典型制造业产品零部件最佳供货模式,并使用关联规则处理策略,对发现的结果进行进一步处理,有效地降低企业成木,提高客户满意度、增强企业的竞争力。实践证明该方法在离散制造企业中具有较大的使用和推广价值。
(本文不涉密)
责任编辑:
上一篇:路面铣刨机操作规程
下一篇:电子商务是SaaS发展的突破口
特别推荐





 |
站点信息
- 运营主体:中国信息化周报
- 商务合作:赵瑞华 010-88559646
- 微信公众号:扫描二维码,关注我们
